Post-Failover Options
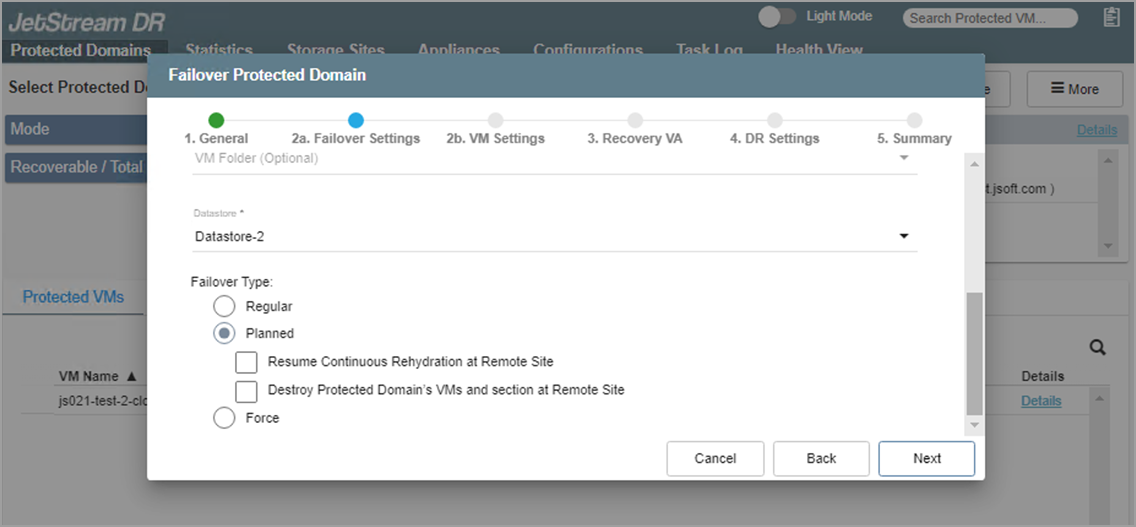
Multiple options are available to control the state of the protected site and ownership of VMs and data after failover has been completed. Failover can be completed in one of three ways: regular, planned, or forced.
Modes to complete failover.
- Regular Failover: Follows the set course of steps for normal failover mode.
- Planned Failover: Starts recovering data from the object store to the recovery site while VM(s) in protected site are still operational. It shuts down the VM(s) gracefully in the protected site when most of the data has been recovered and then stops the domain. It recovers the remaining data, transfers ownership of the domain to the recovery site, executes runbook (if configured) and then completes the task.
- Planned failover is typically used for non-disaster related events such as seamlessly shifting the location of VMs and their workloads while they continue to operate (i.e., migration).
- For example, if it is known an event will occur that would produce a large workload or data burst that exceeds the resource capacity of the on-premises site, it could be beneficial to shift the VMs and their workloads to a cloud services provider capable of meeting the demand.
- Another common case is moving VMs and workloads away from the on-premises site before performing major site maintenance that could potentially be disruptive or risky. After maintenance is complete, the VMs and workloads can be non-disruptively “failed-back” to the updated on-premises site.
Note: During planned failover, any running VMs will be gracefully shut down by the MSA. VMware tools should be installed on all protected VMs to ensure proper operation of the shutdown process. If any VMs cannot be automatically shut down by the MSA they will need to be manually powered-off and then the task should be re-run. In general, it is recommended to install VMware tools on all VMs that will be protected.
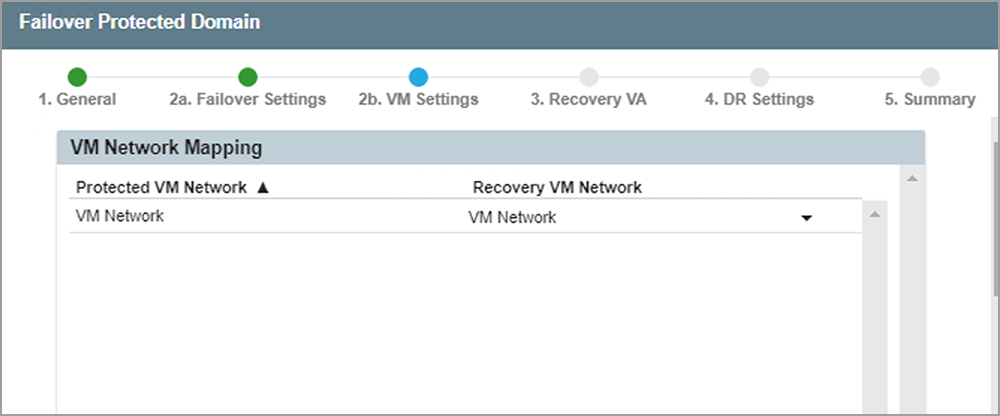
Specify failover network details.
- Maximum delay after stopping option: During planned failover, VMs running on the primary site are shut down as final bits of data are transferred prior to switching to the recovery site. Depending upon the amount of remaining data, this process may create some downtime on the VMs. The maximum delay function allows a hard limit to be set on the allowable downtime introduced by this process.
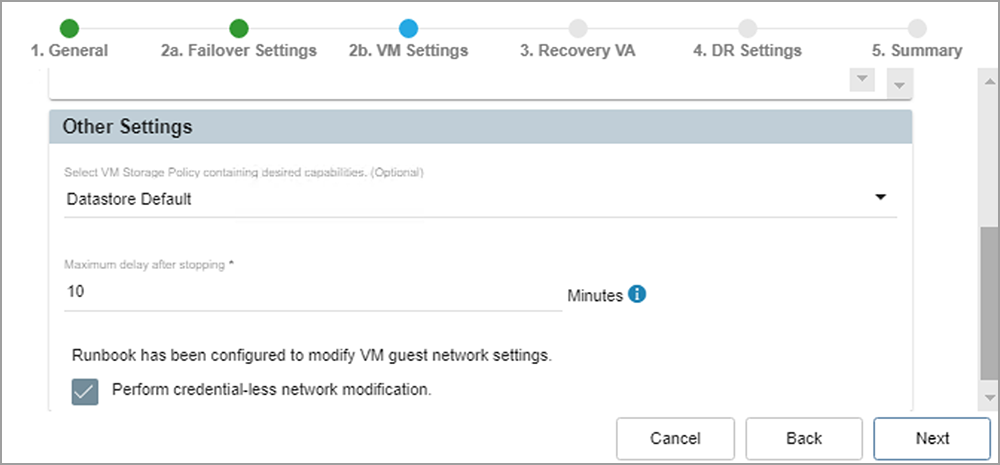
Specify planned failover maximum delay.
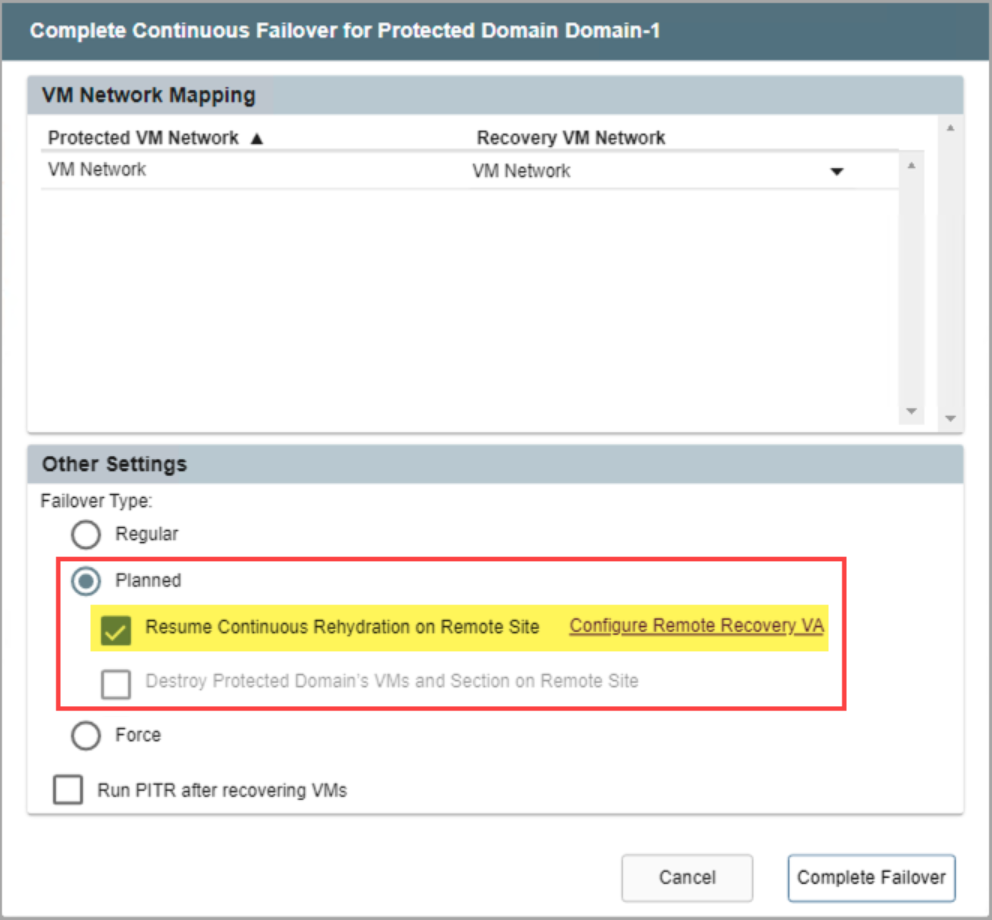
- If planned failover is used, a sub-option is available to Resume Continuous Rehydration on the Remote Site.
- Planned failover using the continuous rehydration option is in essence “continuous failback.” Once VMs and data have been failed over to the recovery site, any new data generated there will automatically be “rehydrated” (synchronized in the background) back to the original protected site allowing for “near-zero RTO” failback.
- Click the Configure Remote Recovery VA link to configure continuous rehydration settings. (It is typically configured to run automatically upon failover.)
- Destroy Protected Domain's VMs and Section on Remote Site option: Deletes the VMs from the datastore and the section from the protected site after planned failover completes.
 z
z
Planned failover mode options.
- Certain conditions must be met to use the Resume Continuous Rehydration on Remote Site option.
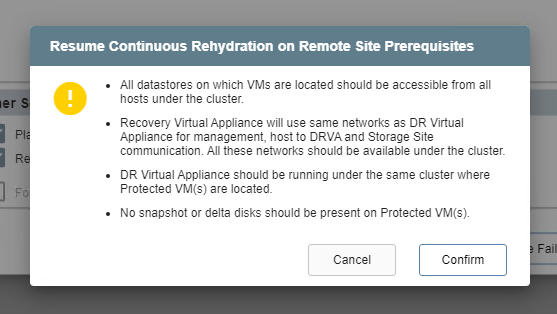
Resume continuous rehydration.
- Forced Failover: Assumes the primary site is no longer accessible.
- Ownership of the protected domain is immediately passed to the recovery site.
- A dialog window will appear asking the user to confirm that complete ownership of the protected domain can be taken over immediately by the recovery site.
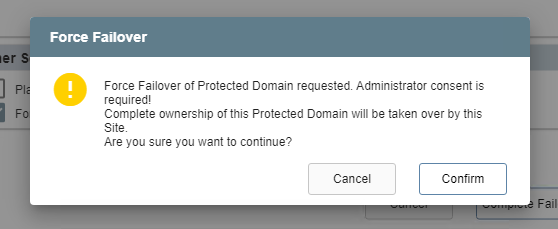
Forced failover.